


When it comes to front-end development, understanding the DOM is crucial. However, this topic can be pretty confusing for beginners, especially due to the complicated lexicon. “Shadow DOM vs. virtual DOM,” for instance, is quite a common confusion among developers, especially junior ones.
In short, the shadow DOM is a browser technology whose main objective is to provide encapsulation when creating elements. On the other hand, the virtual DOM is managed by JavaScript libraries—e.g., React—and it’s mostly a strategy to optimize performance.
Why does the difference matter? These two terms refer to related yet different things, but people often use both interchangeably. Not understanding the difference between these two concepts can lead to problems like miseducation of novice developers and bad technical decision-making. A proper understanding of technical terms is the first step toward productive technical conversations.
Shadow DOM vs. Virtual DOM: Going Deeper
Let’s cover the difference between the shadow DOM and the virtual DOM in more depth. But first, let’s make sure we’re on the same page regarding the regular DOM.
What Is the “Real” DOM?
What is the DOM in the first place, and what’s it all about? DOM stands for “Document Object Model.” It’s a representation of a webpage structure in the form of a tree, in which each element of a page (roughly speaking, each HTML tag) is a node.
Your browser assembles the DOM from the HTML code it receives from a successful GET request. Keep in mind, though, that the DOM isn’t identical to the HTML code. For instance, browsers are typically very forgiving of errors in an HTML document and will do what they can to “guess” what the correct intention was and fix the issue.
The neat thing about the DOM is that it acts as an API to the web document. It allows you to programmatically interact with the elements of a page. That’s basically what you’ll do in client-side applications, of course: DOM manipulation. Also, the possibilities for testing are many when it comes to the DOM. From tools like Selenium to approaches like using headless browsers, the DOM is omnipresent.
Seeing the DOM
I’ve created a simple webpage to use as an example. This is what the page looks like:
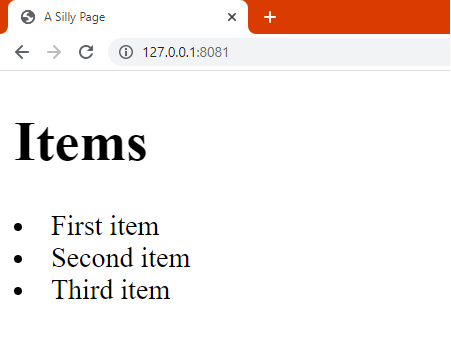
Well, I’ve told you it was silly, didn’t I? Anyway. This is what I see when I use Command + Option + C to inspect the page’s source code:
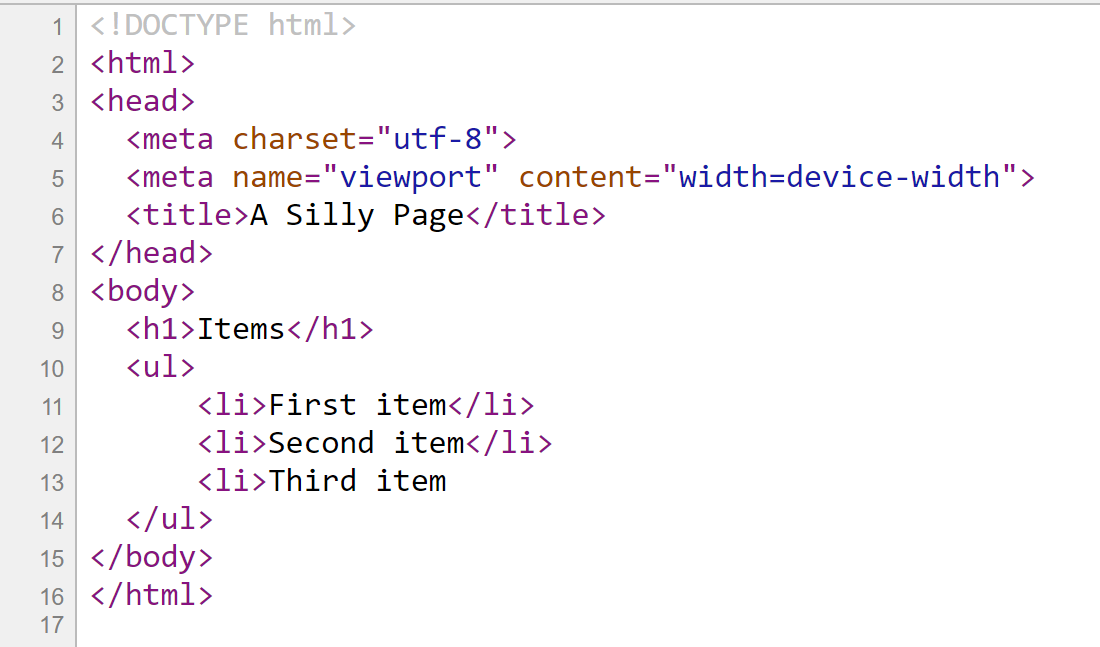
As you can see, the third item on the list is missing its closing </li> tag. However, let’s now inspect the DOM. On Chrome, I press F12 to invoke the developer tools and then go to the “Elements” view. This is what I see:
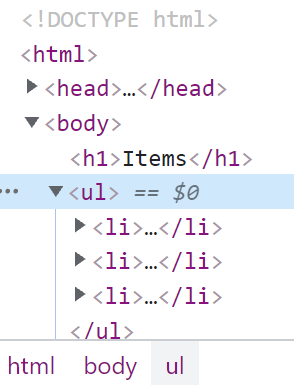
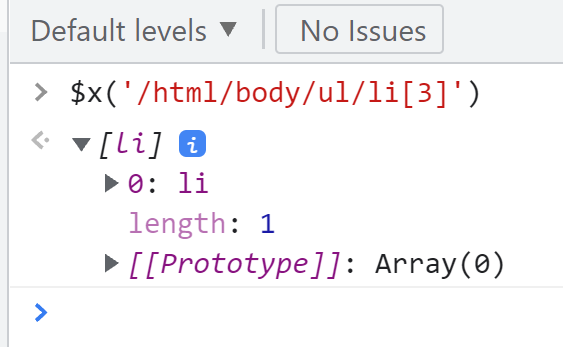
As you can see, the browser representation is smart enough to add the missing closing tag. We could even use XPath to locate the third li element correctly:
What Is the Shadow DOM, and How Is It Different From DOM?
With the regular DOM 101 stuff out of the way, let’s now move to the shadow DOM. How does it differ from the real DOM, and why should you care?
The shadow DOM is a relatively recent API whose goal is to provide encapsulation when implementing web components. The idea is to allow you to implement an element without worrying it will clash in some way with the rest of the webpage. A classic example of the kind of problem that the shadow DOM solves is CSS issues due to auto-generated classes.
The shadow DOM is a browser technology. According to the MDN Web Docs by Mozilla, this is the list of browsers that support shadow DOM:
- Firefox, starting at version 63
- Chrome
- Opera
- Safari
- The new Microsoft Edge (based on Chromium) starting at version 79
Let’s see a silly—to continue on the theme—example (some tags were edited out for brevity):
<style type="text/css">
p { color:green }
</style>
</head>
<body>
<script>
customElements.define('course-card', class extends HTMLElement {
connectedCallback() {
const shadow = this.attachShadow({mode: 'open'});
shadow.innerHTML = `
<style> p { font-weight: bold; color:blue } </style>
<p>
Welcome to the course ${this.getAttribute('title')}
</p>`;
}
});
</script>
<p>This paragraph isn't blue!</p>
<course-card title="Learn Frontend Testing"></course-card>
This is what I see when visiting the page served by my local server:
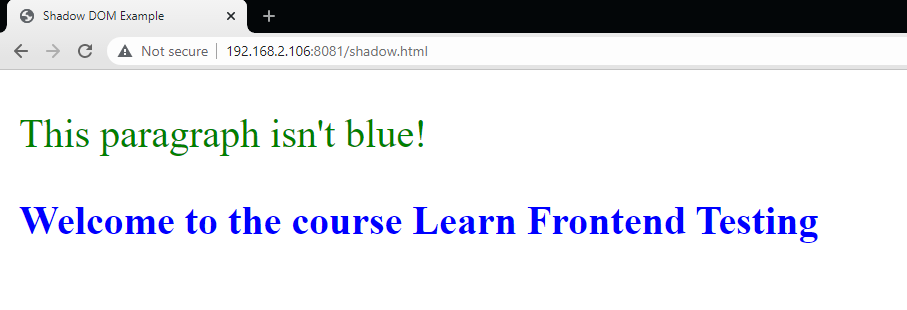
As you can see, the external style defining the font color for paragraphs as green didn’t affect the internal style of our custom component. The opposite also didn’t happen: in other words, the embedded style of the component didn’t affect the global styles either.
And this is my view on Chrome’s developer tools:
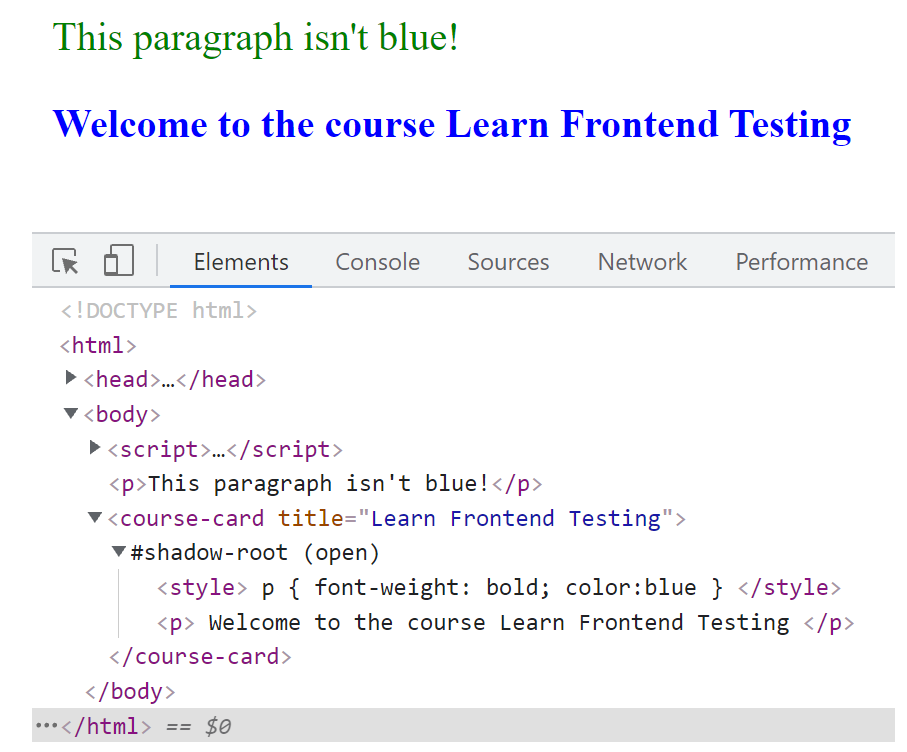
What Is the Difference Between DOM and Virtual DOM?
Let’s now cover the virtual DOM and how it differs from the real DOM. But first, let’s understand what the problem is with manipulating the real DOM in the first place.
First of all, code that manipulates the DOM is typically very imperative/procedural. For instance, the following code excerpt retrieves the first list item from the previous example and changes its content:
var item = document.getElementsByTagName('li')[0];
item.innerText = 'A different text';
It doesn’t look that bad for this silly example of ours. But when we’re talking about a large application, with rich interactions and complex logic, code can become quite messy very quickly.
However, the main concern when it comes to DOM manipulation is performance. DOM rewrites are costly, so you want to do them sparingly. That’s where the concept of virtual DOM can come in handy.
The virtual DOM is a “virtual,” in-memory representation of the DOM. Since it lives in memory, manipulating it is less costly than handling the real DOM.
Libraries such as React use the concept of virtual DOM to abstract the real DOM away from the developer. When you use React, for instance, you define the desired state of each component in a declarative way, with JSX code or calls to React functions. React then does what it needs to reconcile its virtual DOM with the real DOM, only changing what’s necessary, so you don’t have to bear the cost of real DOM rewrites.
Is the Shadow DOM the Same as the Virtual DOM?
Finally, one last important question. Are the shadow DOM and the virtual DOM the same? No, they’re not. They’re totally different things. As you’ve seen through the post, they have different purposes, are implemented at different layers, and are relevant in different contexts.
The following table summarizes the differences between the two concepts:
| Shadow DOM | Virtual DOM | |
| What It Is | An API allowing developers to attach a “hidden” DOM to an element for encapsulation purposes | An in-memory representation of the DOM |
| Purpose | Encapsulate logic and presentation inside an element, protecting it from effects from the rest of the page | Abstract the real DOM away, allowing for better performance and a more declarative style of coding |
| Who Implements It | Browsers | JavaScript libraries, such as React and Vue |
Conclusion
Confusing terms such as shadow DOM and virtual DOM can make understanding the DOM trickier. They sound like they could refer to the same concepts, and many people use them like they’re the same. But they’re not, and in this post, you’ve learned how they differ.
This knowledge can help you in several ways. For instance, if you’re a React developer, understanding how the virtual DOM works—and the React life cycle as a whole—might allow you to adopt strategies to avoid unnecessary reconciliations. Learning about shadow DOM means you can use it to enjoy its encapsulation benefits when writing your custom web components.
What should your next step be? Well, since we’re all about testing here at the Testim blog, my suggestion is for you to investigate how these concepts affect front-end testing. Here’s an excellent post about some of the challenges the shadow DOM can bring to testing and how Testim handles them.
What to read next?
Handling Dynamic Classes in Test Automation: Why You Don’t Need to Care


