


At Testim, we are always trying to improve our Smart Locators to keep track of your elements better to achieve the most stable tests possible. Some attributes can be trickier than others. One Dev practice that creates challenges is the use of random GUIDs to generate class names.
In this post, we will describe what these are and how Testim handles them automatically.
Why do devs use randomly generated class names?
As web applications grow and increase in complexity, the size of the team working on the application is also likely to expand. Development teams should work in isolation without fear that a class name they create will bump into the same class name used by another team. Clashing class names can cause logic conflicts or one class definition overruling another.
CSS didn’t support working in isolation until recently, and the standard way of handling potential conflicts was to augment the class names via a tool like CSS modules. CSS modules would replace or append the class names with a random number/GUID to ensure class names were unique.
Aside: There’s a new and rising approach for avoiding these CSS conflicts called Shadow DOM. For now, many web applications use CSS modules to support old browsers. To read more about how Shadow DOM is automatically handled with Testim, read our blog.
What are the challenges it causes for test automation?
Since the class names are appended with randomly generated numbers, each build could drive a different class name. If you are using a test automation tool looking for a particular class name, and that name is changing with every build, you can see how it would impact stability.
There are a couple of workarounds to get around dynamic class names with coded solutions (like Selenium and Cypress). First, you could use the config to combine the original class name along with the random-generated portion and change the selector from “equals” to “contains” (for example from .name to [class=~name]). Second, you could choose another attribute as the selector for the element. Of course, this has its own challenges if the other attributes aren’t better at identifying the element uniquely.
Expand Your Test Coverage
How does Testim solve it?
First of all, Testim’s smart locators use many selectors and the relationships between the selectors to lock in each element. Thus, it’s not dependent on a single class name to identify the element. That said, if multiple class names are frequently changing it could reduce the confidence of the locator below your tolerance.
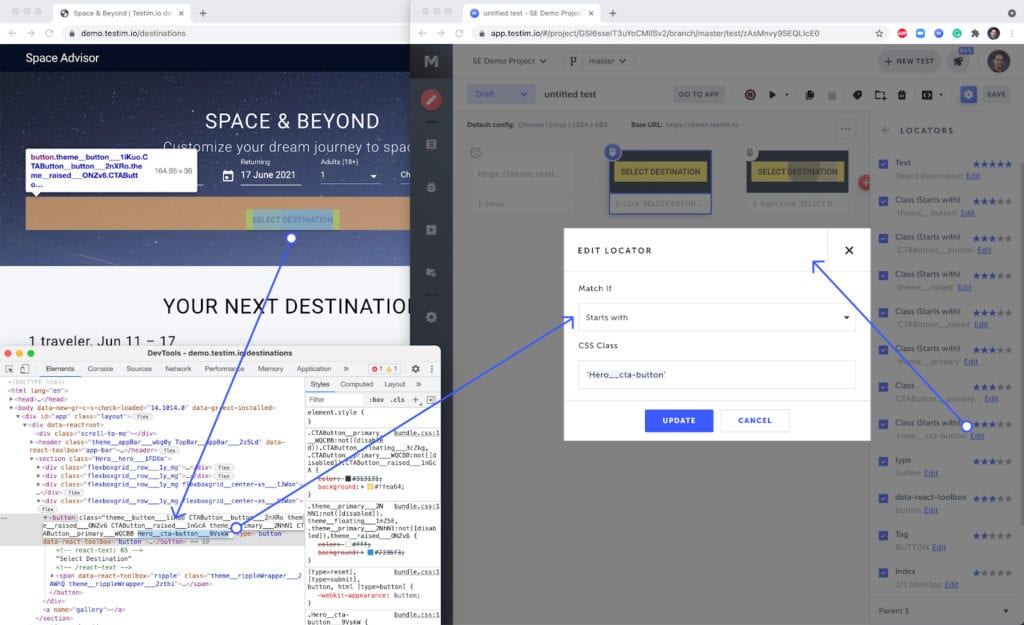
To account, Testim also identifies when dynamic class names are used and applies both of the strategies above to locate the element. For instance, Testim determines that the attribute contains random values and automatically updates the locator to search only for the consistent part. Secondly, as mentioned earlier, Testim’s Smart Locators utilize multiple elements in identifying and locking in the elements. Thus, our approach to finding page elements isn’t dependent on a single selector but rather the aggregate score that our AI determines from many attributes.
BTW, if for some reason, Testim doesn’t automatically identify the random CSS, you still can edit the locator properties and apply this technique manually.
The wrap-up
These random class names may be good for preventing conflicts between developers, but they can create havoc for most codeless automation tools. Fortunately, Testim handles this challenge automatically to improve your test’s stability. After all, making hard testing problems go away is why many customers chose Testim.


