


What Is XPath?
Advantages of Using XPath
- XPath allows you to navigate up the DOM when looking for elements to test or scrape.
- It’s compatible with old browsers (or it was at time of publishing—including older versions of Internet Explorer, which some corporations still use).
- Creating in XPath is more flexible than in CSS Selector.
- When you don’t know the name of an element, you can use contains to search for possible matches.
How to Create an XPath
XML path syntax uses tree diagram type flows to locate elements on an HTML page. Consider the form element in the search page markup below.
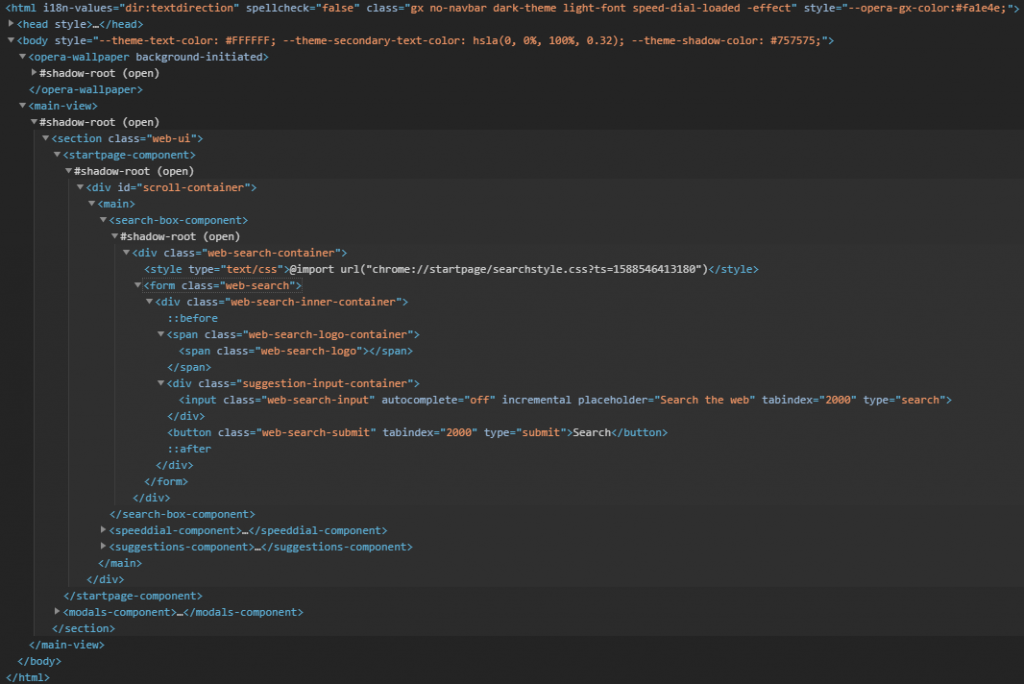
The full XPath to the search button inside the form would look like this:
/html/body/main-view//section/startpage-component//div/main/search-box-component//div/form/div/button
As seen in the full XPath, the document is broken down into the elements that essentially represent its skeleton. Going from top to bottom within the resulting document and listing every node, until you reach the desired element, is what becomes the XPath. Here’s a shorter way to write this.
//*[@id="scroll-container"]/main/search-box-component//div/form/div/button
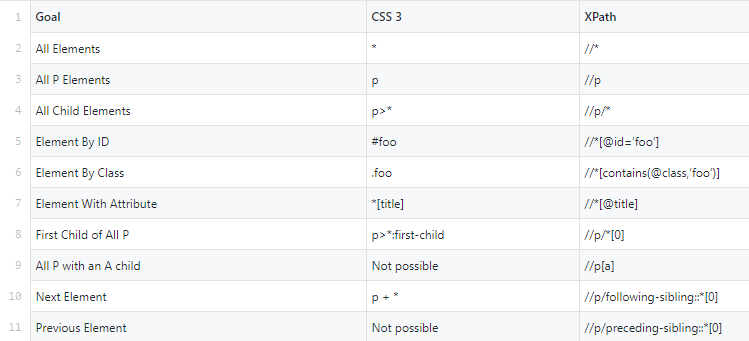
And here’s a comprehensive table for the syntax of both XPath and CSS Selectors;
What Is CSS Selector?
- Simple selectors: These search for elements based on their class or ID.
- Attribute selectors: These pick up elements based on values assigned to them. I’ll provide some examples later on in this article.
- Pseudo selectors: In situations where the states of elements are declared with CSS, such as check boxes or on-hover attributes, these come into use.
Advantages of Using CSS Selector
- It’s faster than XPath.
- It’s much easier to learn and implement.
- You have a high chance of finding your elements.
- It’s compatible with most browsers to date.
Expand Your Test Coverage
How to Create CSS Selectors
Let’s use the same image that we did earlier, with a search page’s markup displayed. You can do this on any web page by right-clicking and selecting Inspect Element. You should be able to create the CSS selector just as we did with the XPath.
In this case, the CSS selector would look like this.
div > form > div > button
Notice how much easier it is to read the CSS selector compared to the XPath. You can read this as, “The button is a child element of the div inside a form, which is itself inside the div type selector.”
To fully cover what’s possible with the CSS attribute selector, let’s consider a more specific markup example.
<ul>
<li><a href="maps.google.com"> Google Maps Sub-domain </a></li>
<li><a href="mail.icloud.com"> Link to iCloud Mail Services</a></li>
<li><a href="mail.opera.com"> Opera Mail </a></li>
<li><a href="mail.google.com"> Gmail Services </a></li>
</ul>
The selector applicable for finding specific elements in the above example would look like this.
a[href^="some value here"]
For instance, let’s say you want to pick out the <a> element that includes “mail” as a value. In that case, you’d use the * sign after the href key. This would give you:
a[href*="mail"]
This returns all the elements but the first one because it doesn’t have mail as the sub-domain.
What about instances where you’d like to select all elements ending in a certain value? Then you’d replace the * with a $. You can filter out entries that start with a certain value by using the ^ sign. There are plenty of such signs depending on the rules you’re using for selection.
Now you’ve had a mini tour of each option. So which one is right for you?
Which to Use: XPath or CSS Selector?
When you’re deploying software a product to a group of users, time is often of the essence. This statement alone should let you know what option is better for you to use. If your software testers decide to make their own test automation scripts, using the option that they already have experience with is the way to go. Besides, the execution time difference between XPath and CSS selectors is not such that you could do meaningful work while others wait. Such a negligible difference means that both options may be running neck-and-neck for you at this point.
As I mentioned at the start of this article, your environment kicks in more than any other variable. A limiting factor when dealing with selectors is the fact that they get more complex as the type of element evolves from simple through pseudo to combinators. Multiple selectors would also make it more complex to even use selectors in the first place.
“There has to be a better way of implementing test automation!” you might say. As with most repetitive processes, artificial intelligence is beginning to affect both options. Services like Testim have figured out quicker and more intuitive ways to run tests on elements on the DOM.
In the past, you had to generate paths or pinpoint selectors in the back-end by combing through all the markup. Now, services such as Testim take care of that for you. The company uses its artificial intelligence and algorithms to look at the entire DOM and identify elements by multiple attributes. Testim will look at class, parent/child, color, text, type, ID, or other attributes and find the item for you to run your tests. Using such a service stops your focus from being focused on XPath vs CSS Selector. Instead, you can focus more on the results.
Also, if you use Testim, working on the front end when creating automated tests also makes it easy to deploy products faster. You can use fewer code-critical skills to iterate on the testing and feedback phase of a product’s development life cycle.


