


The technology industry is becoming more and more competitive with each passing year. Organizations around the world struggle to remain afloat. They employ strategies to improve the quality of their products and services. They adopt test automation to obtain shorter release cycles. However, many companies don’t actively track their progress (or lack thereof) when it comes to quality improvements, which threatens to make the whole effort futile. If we accept that we can’t improve what we don’t measure, then QA metrics become crucial to improving quality in our organizations.
So, it’s obvious that understanding QA metrics and knowing which ones to adopt is essential. That’s what today’s post is about.
We’ll start with the fundamentals—that is, the “what” and “why” of QA metrics. Then, we’ll list some of the main properties of a great QA metric, which should help you pick the right indicators for your scenario. Then we’ll make your life even easier by listing the seven QA metrics your organization should consider adopting before sharing our final thoughts and calling it a day. Let’s get started.
QA metrics fundamentals
As promised, let’s start with the basics. What do we mean by QA metrics, and why are they important? That’s what we’re going to see now.
What are quality assurance metrics?
Since QA stands for quality assurance, we could define QA metrics as “indicators related to quality assurance.” That definition would be as short as it is useless, so we’re going further than that.
First of all, let’s define quality assurance. This term—much like “testing,” recently—has become a loaded term. It can mean quite different things to different people, so it’s important that we’re on the same page here.
Quality assurance refers to techniques and processes supposed to ensure the highest possible quality for an organization’s service or product. That’s a key difference between QA and QC (quality control): while the latter aims to find and fix problems, the former encompasses activities to prevent the defects from being created in the first place.
Quality assurance refers to techniques and processes supposed to ensure the highest possible quality for an organization’s service or product.
With the “QA” bit out of the way, we’re now left only with metrics, which makes it easy for us to come up with a complete definition:
QA metrics are indicators we should track and improve to ensure that our QA processes are as healthy and efficient as possible.
Why care about metrics?
The investments required to design, implement, and maintain a comprehensive QA strategy aren’t trivial. That would include the cost of cloud provider fees, employee training, licenses for various test automation tools, and more.
Making the colossal investment into a QA effort without having the means to verify whether it’s working or not isn’t business-savvy. In fact, you could argue that having a QA strategy in place and not knowing its ROI is worse than not having one at all, and I’d be hard-pressed to disagree.
That’s why QA metrics are vital. By tracking them, teams can understand where their quality strategy is succeeding and where it’s falling short, which is the first step toward improving it.
The properties of great QA metrics
There’s a potentially infinite number of possible QA metrics. And of course, some are more valuable than others, which means that you must pick the ones that make the most sense for your current scenario, even if that changes in the future. With that in mind, what are the criteria you should have in mind when choosing the QA metrics for your organization?
The first property of a great QA metric is “zero subjectivity.” In other words, it should be not only objectively measurable but also actionable. You must be able to measure it and then do something about it.
Second on our list is “up to date.” An outdated metric is useless since we’re not solving last year’s problems. A great QA metric is one that’s constantly updated.
Finally, a great QA metric is one that’s relevant to the business. If you have a metric that’s measurable, actionable, and constantly updated but is totally meaningless for the business’s goals, it’s going to be very hard to justify its return on investment.

QA metrics at different levels
When discussing the relevance of a QA metric, it’s also important to bear in mind that QA metrics aren’t relegated to a single area or level in the organization. Rather, there are different levels or tiers in which a given metric can exist and be relevant. For instance, you might have metrics at the project level. There are metrics related to the number of defects over a given period, for instance. Such metrics are most relevant for their specific products, though you can also consider them at the department level.
When discussing the relevance of a QA metric, it’s also important to bear in mind that QA metrics aren’t relegated to a single area or level in the organization.
Other metrics, on the other hand, might be more useful at different levels. For instance, one of the metrics we’ll discuss shortly is MTTD (mean time to detect.) In short, the lower value of MTTD, the better, since that means the organization has good diagnostic capabilities. It makes sense for MTTD to be considered at the organization level since its value reflects the quality of the organization’s incident response capabilities.
Seven QA metrics worth adopting
From the beginning of the post until now, we’ve covered the basics of QA metrics. We’ve started by defining the term. Then we’ve proceeded to explain why QA metrics can be so valuable for modern software organizations.
Even though metrics are important, not all of them are equally valuable. Some are amazingly helpful and others, less so. We’ve addressed that by covering some of the main characteristics you should look for when trying to pick the right metrics for your organization.
Now we’re going to go the extra mile by actually listing seven examples of QA metrics you might consider adopting at your organization. Let’s dig in.
1. Mean time to detect
The first item in our list is MTTD, which stands for mean time to detect. As its name suggests, this metric refers to the mean time it takes the organization to detect issues.

What’s the relevance of this metric? Simply put, the sooner you discover a problem, the sooner you can fix that problem. When you measure how much time it takes to discover issues, you’re taking the first step towards improving said time. And it’s been known for quite a while that it’s cheaper to fix an issue when you discover it earlier.
2. Mean time to repair
Our second metric is called mean time to repair, also known by its acronym, MTTR. It makes sense to add it as the second item in our list since it’s sort of a sequel to MTTD.
So, what’s this metric about? MTTR means exactly what its name suggests: it’s the mean time an organization takes to repair problems that cause systems outages.
Calculating MTTR isn’t hard since it just consists of three steps:
1. For a given period, find out the total amount of downtime.
2. For the same period, count the number of incidents.
3. Divide the first number by the second one.
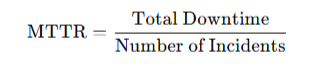
That’s pretty much it. So, why is MTTR so important? The answer should be almost self-explanatory: when systems are down, you’re not making money. Tracking this metric and keeping it as low as possible is essential if you want to ensure everything is running smoothly.
3. Test reliability
This might sound like a subjective metric, but it’s not. Test reliability—which might be known by other names, such as test robustness, or its antonym, test flakiness—refers to the number of test cases that don’t provide useful feedback due to them being unreliable.
What makes for an unreliable test? Think of unit tests, for instance. A great unit test is deterministic. That is to say, if it’s passing, it’s going to continue to pass unless some change is made to the code. The opposite is also true: if a given test is failing, it should remain that way as long as you don’t change the code of the SUT.
So, an unreliable unit test would be one that’s not deterministic. Sometimes it passes, sometimes it fails, in a seemingly arbitrary way, which undermines the confidence of developers and other professionals in the test suite.
4. Test coverage
Another essential QA metric is test coverage. People often mix it up with code coverage, which is understandable but wrong. So, what’s test coverage really about? And how does it differ from code coverage?
We have a whole post about that, but here’s the short version: code coverage is a metric that refers to the portion of the codebase that’s covered by unit tests. Test coverage, on the other hand, is a much broader metric. It means making sure your tests—of various types, and not only unit tests—are able to cover most of the facets of your product.
5. Code coverage
Code coverage is an important testing and quality metric on its own. As we’ve just mentioned, code coverage refers to the ratio of the codebase that is exercised at least once by an automated unit test.
There are actually several ways to go about calculating code coverage. The most naive—and less useful—one is what we called line coverage. It simply refers to the number of lines covered by tests divided by the total number of lines. Why do we call this form of calculating code coverage naive? Well, it doesn’t tell the whole picture. You could have 100% line coverage and still have scenarios that aren’t tested, because of conditional branching (e.g. if statements) inside your code. That’s why the best modality of code coverage is branch coverage. Branch coverage actually verifies the portion of the branches in your application that are exercised through testing.
Branch coverage is particularly important because of its relation to cyclomatic complexity, a metric that’s a predictor of how hard it is to test a given piece of code.
6. Escaped defects found
This metric refers to the number of defects found in production.. In other words, these are the issues that have “escaped” your QA strategy and slipped into the client’s hands.
This is one of the most important measurements in QA since it’s directly tied to the performance of your QA strategy. An efficient quality assurance approach should result in fewer defects in production. Conversely, a high number of escaped defects necessarily means that the QA strategy has room for improvement.

7. Defect distribution
This isn’t really a single metric, but a category of them. Defect distribution consists of measuring the number of detects or bugs according to different criteria. Those criteria include factors like severity, area of the application, or even the testing type.
8. Defect detection percentage (DDP)
The purpose of this metric is to measure how effective a QA process is by calculating the percentage of the total defects that the QA team catches before release. It can be calculated by the following formula –
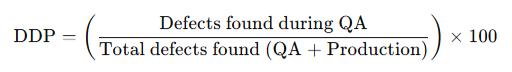
A high DDP shows a strong QA process that minimizes the issues reported by customers.
9. Test execution time
Test execution time tracks how much time a full suite of tests takes to execute. Monitoring test execution time helps QA teams to identify performance bottlenecks in the QA pipeline and optimize accordingly, resulting in faster feedback loops. A test execution time that is rising consistently signals inefficiencies in the testing infrastructure or a complex test suite.
10. Test case effectiveness
Finally, we’ve reached the last item on our list: test case effectiveness. This metric compares the count of defects found through test cases to the total count of defects discovered. The goal is to find out how well bugs are caught by test cases. This is useful to find out whether the test suite is providing high coverage value and targeting the right areas of the application.
Now that we know about the metrics, let’s find out the solutions that may arise while implementing them.
Challenges in implementing QA metrics
While implementing QA metrics, teams may face challenges like:
- Inconsistent or manual data collection, affecting accuracy.
- Often, teams may resist by mistaking metrics for micromanagement.
- Absence of proper objectives may lead to misleading or irrelevant metrics.
- Lack of automation may increase workload.
- If metrics are misinterpreted, it may lead to poor decision-making.
Even after facing these challenges, here are some practical steps that you may follow to ensure the smooth and successful implementation of QA metrics.
- Adopt automation tools to reduce manual processes and standardize data collection.
- Ensure accuracy and consistency of data across teams.
- Define clear goals that are aligned with business and QA objectives.
- To build trust, involve developers and the QA team before selecting metrics.
- Promote metrics not as performance surveillance, but as improvement tools.
Here be dragons: A caveat about QA (and other) metrics
In this post, we’ve explored the subject of QA metrics. We’ve defined the term, explained why metrics are essential to evaluate ROI when it comes to your QA strategy, listed the qualities of great QA metrics, and even listed the seven essential metrics your organization should consider adopting.
Now we leave, but not without a word of warning: beware of metrics when they become targets. When you tie certain outcomes to metrics, they immediately stop being useful measurements and instead become just hoops for people to jump through. For instance, tying bonuses with certain metrics might encourage employees to game said metrics. If the team institutes some positive outcome related to achieving a high code coverage, that might cause engineers to just write tests to reach the target and completely disregard unit-testing best practices.
A similar thing could happen with a different, non-testing metric: number of commits. What if the company decides that the more commits the better? And, most importantly, attaches some reward to that number? Then, engineers might feel encouraged to split up their work into unnecessarily small commits. A final example, related to the world of agile: when managers make the mistake of using velocity as a performance indicator, developers might also gaming the metric, by inflating their story points estimation.
The takeaway here is this: metrics can be double-edged swords. They’re amazingly effective, but they can also be dangerous if you don’t wield them with caution. Thanks for reading.
Carlos Schults wrote this post. Carlos is a .NET software developer with experience in both desktop and web development, and he’s now trying his hand at mobile. He has a passion for writing clean and concise code, and he’s interested in practices that help you improve app health, such as code review, automated testing, and continuous build.


