

")
You can grow a garden of comprehensive tests for your codebase in many ways. Today we’ll discuss data-driven testing.
As your software grows, so do the number of tests to ensure your code works smoothly. This situation can easily become a burden, allowing your tests to grow like weeds, becoming hard to read and maintain. Eventually, you may give up, reducing your testing—and opening the path to defective code. With data-driven tests, you can ensure your garden of tests bears much fruit.
Today, we’ll cover why data-driven tests are important. You’ll see examples of how tests can grow like weeds. You’ll find out how to data-drive your tests, and you’ll see some dos and don’ts that will help you succeed.
Why Data-Drive Your Tests?
At this point, you may be wondering why data-driven tests are so special. I believe they give you two main benefits.
- They reduce the cost to add new tests and to change them when your business rules change. How? By creating parameters for different scenarios, using data sets that the same code can run against. We’ll look at an example of this process in a moment.
- They make it easy to find out what data is most important for the tested behavior. By separating first-class scenario data into parameters, it becomes clear what matters most to the test. This process makes it easy to remember how something works when you need to change it.
The Journey
Let’s journey through how some innocent-looking tests can get out of control. For this example, you’ll look at the software that automatically edits a blog post. This software can detect syntax problems, correct grammar, and perform many other tasks quickly and easily.
We’ll test-drive the code in C# with the XUnit test framework. Xunit is a strong choice for most .NET testing because of its simplicity and the lessons learned from older test frameworks. For Java, you can use JUnit 4 or higher. Alas, JUnit’s data-driven tests aren’t quite as clean.
Without further ado, here is our journey to a weedy garden of tests.
1. We Plant a Seed
Let’s start simply with a test that ensures there aren’t too many spaces in a blog post. This test represents each space with a period to make it clear how many there are. I wouldn’t want you to have to squint to count each whitespace or believe that two similar but different tests are exactly the same. Here’s the code.
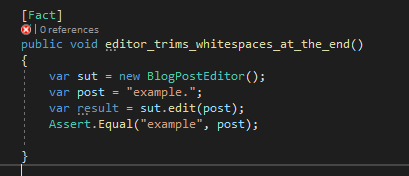
2. We Get in the Weeds
As you deal with more places that spaces can appear, your test suite grows longer. This is starting to become a problem.
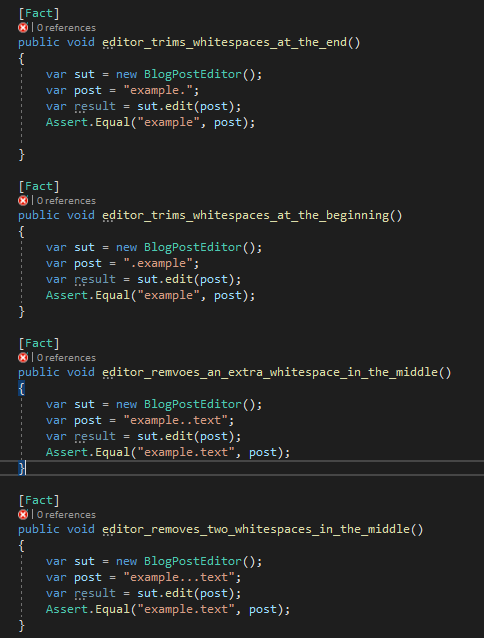
As you can see, if you add many more editing rules, it will be hard to understand how the editor behaves—even just for spaces. It feels like we barely scratched the surface of the problem, but it’s already overwhelming. We still haven’t even tackled removing spaces for more than two words.
3. We Try to Weed Out the Mess
You can refactor this into a loop of sorts:

You can see that we took the meat of each test and extracted it into a loop. We also took the data the test uses and put it into a dictionary. But even with these changes, how do you know which scenario fails? Without special code, you don’t have the ability to tell the test runner which scenario you’re in.
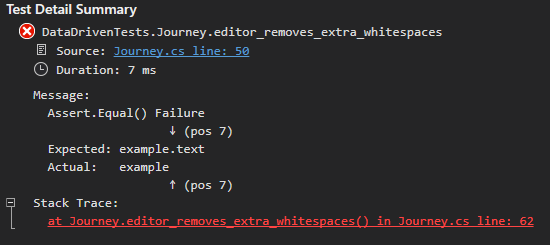
Sometimes you can figure out which scenario failed based on the failure. But for the most part, you don’t know which set of inputs caused the test to fail.
4. We Bear Fruit With Data-Driven Tests
Let’s refactor these into a data-driven test, as supported by Xunit:
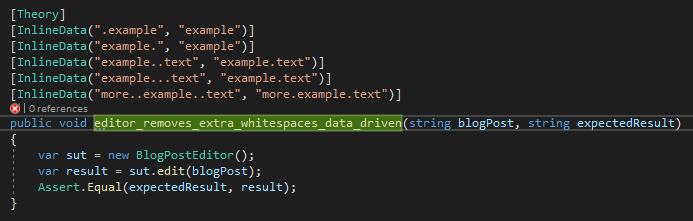
Let’s look at some key aspects of this code.
- The [Theory] annotation marks a test as a data-driven test.
- Each scenario is in an [InlineData()] annotation.
- The behavior is the same, but it uses the parameters blogPost and expectedResult.
Notice that you can easily add a three-word scenario with only one short line of code:
[InlineData(“more..example..text”, “more.example.text”)]
Data-driving tests in this way derives a test for each scenario:

Now when failures happen, you can clearly see which scenario failed the tests:
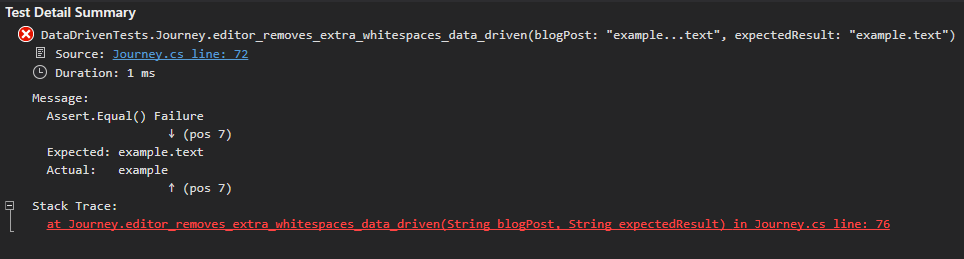
That’s really all there is to creating data-driven tests: detect similar scenarios and create parameters for key data. The more clear and concise you are, the better.
Some Dos
Now that you understand the gist of data-driven tests, here are some healthy practices.
1. Follow Themes
You’ll want to create parameters only for scenarios that center around similar behavior. Take these tests, for example:
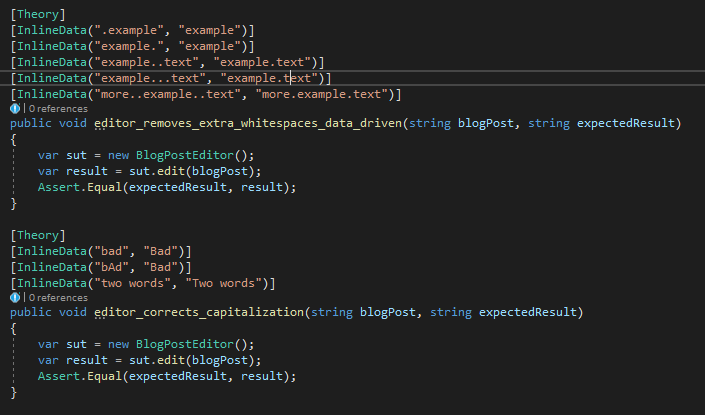
Even though the tests are structurally similar, you’ll want to optimize for readability. The test description and sets of data make it clear what behavior you’re testing.
2. Use Shared Language With Your Business Stakeholders
When making data-driven tests, use language that both your team and your business stakeholders can easily understand. This is useful advice for any form of testing. But in data-driven tests, you can remove a lot of friction if you show the data you’re testing against directly to your stakeholders.
For the blog editing example, you’ll want to ensure you describe your tests with blog editing jargon. You may want to mention copyediting, paragraphs, sentences, posts, links, and so on. For instance, if you’re checking for indents, you may have a test called “edit function indents all lines of text.” That’s way too technical! Instead, you could say “Editor indents sentences.” That’s succinct, and a non-developer can easily understand it.
Some Don’ts
Let’s quickly cover some situations you’ll want to avoid.
1. Avoid Multiple Behaviors in the Same Test
You’ll want to assert the characteristics of only one behavior of the system under the test. This is a data-driven take on “assert only one thing,” a popular phrase in testing.
Here’s an example that gets this wrong because it conflates two forms of editing:
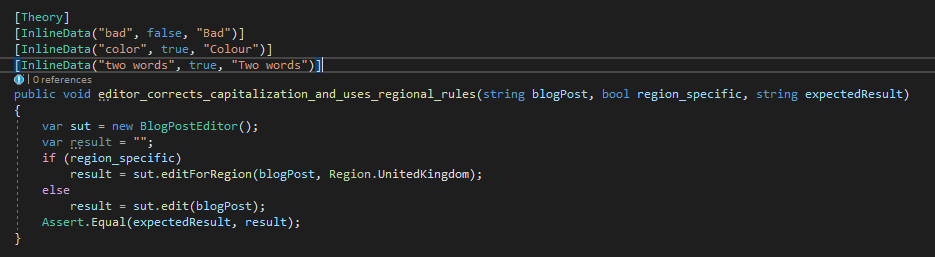
In this case, the rules around regions and the rules around capitalization should be separate. They aren’t even the same method!
This is a rather obvious case, but multiple behaviors can easily sneak up on you in a test suite. Pay close attention to If statements that are actually more complicated than they seem at first.
2. Don’t Overdo It
With the powerful tool of data-driven tests at your disposal, it can be easy to overdo it. You can start creating parameters for everything! Doing so actually decreases the readability of your tests. Take a look at this example:

Here, you’re mixing behaviors and dealing with a lot of parameters. It would be better to split this into multiple tests, ideally following the theming advice from earlier. In this case, you may want to build separate tests for transitions, spaces, and capitalization. Then others could see how each aspect works independently of the others. You may still have an end-to-end test that verifies things work well together, but that test wouldn’t be data-driven. It would be much too generic for that.
Conclusion
As your system grows in complexity, your tests will grow along with it. Instead of creating a weed-infested garden of tests, keep things clean by using data driven testing scenarios that are based on behavior. The results will be a comprehensive, readable test suite that’s easy to grow. Don’t necessarily look for places to do this up front, but let it emerge as your codebase grows.
This post was written by Mark Henke. Mark has spent over 10 years architecting systems that talk to other systems, doing DevOps before it was cool, and matching software to its business function. Every developer is a leader of something on their team, and he wants to help them see that.


